Micro Pogo XPU Socket
AI服务器算力神经中枢
后摩尔时代异构算力互连革新方案,224Gbps高速传输,无残桩微型弹簧针,解决多GPU训练/推理服务器高频信号损耗、高密度布局瓶颈。

AI算力需求爆发
算力规模持续指数增长,芯片制程触碰摩尔定律物理边界
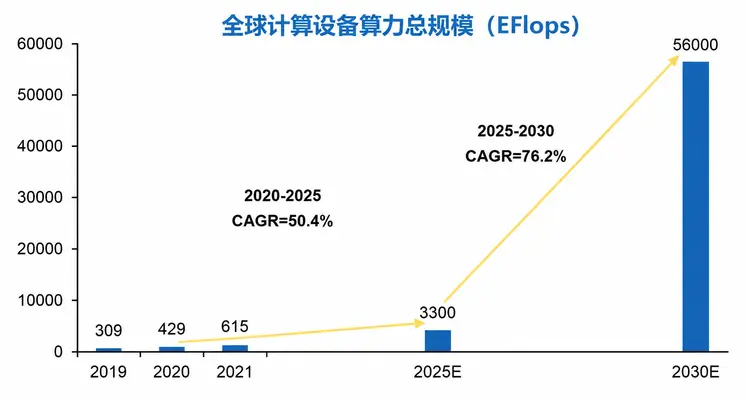
- 2020-2025全球算力CAGR:50.4%
- 2025-2030全球算力CAGR:76.2%,2030年达56000 EFlops
- 数据来源:中国信通院《中国算力发展指数白皮书(2022)》
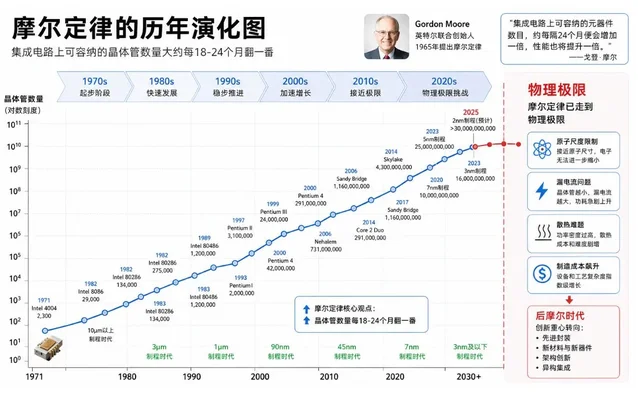
过去几十年,算力增长主要遵循摩尔定律,但现在晶体管尺寸已经逼近物理规律极限。
传统连接方案遇瓶颈
传统冲压弹片式 GPU Socket 成为算力高速传输核心瓶颈

Micro Pogo GPU Socket
拓普联科自研 AI服务器下一代板对板高速互连产品,在56GHz基频,PAM4调制的条件可达224Gbps传输速率
信号频率
56GHz
高带宽设计
传输速率
224Gbps
PAM4调制
工作弹力
25gf
抗震抵消装配公差
Pitch间距
1.0mm
高密度微型阵列
工作高度
1.85mm
压缩总行程0.6mm
Pin外径
< 0.5mm
双形态Micro Pogo 适配AI服务器不同互连场景
双头Pin用于GPU板对板堆叠;单头Pin用于机箱背板、线缆互联
双头Micro Pogo(XPU Socket主力)

适用场景:AI服务器GPU板对板垂直互连、多卡异构算力模组 尺寸区间
尺寸区间
- 直径0.2mm+:Pitch<0.5mm,高度<2mm
- 直径0.3~0.5mm:Pitch 0.5-1.2mm,高度约2mm
核心优势
- 双向弹性浮动,补偿装配公差
- 超薄微型化,高密度阵列排布
- 极低寄生,适配224Gbps高速差分信号
单头Micro Pogo(背板/线缆扩展)

适用场景:服务器高速背板、GPU模组线缆引出、机架互联
尺寸区间
- 直径0.2mm+:Pitch<0.5mm,高度2~10mm
- 直径0.3~0.5mm:Pitch 0.5-1.2mm
核心优势
- 单端接线,适配线缆-板卡互联
- 长行程浮动,兼容机箱装配误差
- 低串扰低损耗,长距离高速传输
Micro Pogo AI服务器全链路落地方案
覆盖板间中短距、芯片间短距、芯片 - 基板超短距三大算力互连技术路线

高速正交背板方案
服务器内部板卡之间中短距离互连适配多板卡并行架构;硬质 PCB 背板走线,高频场景信号损耗偏高

CPC + 高速线缆方案
芯片与芯片之间短距离互连DAC/ACC 高速线缆替代 PCB 走线,大幅降低高频信号衰减,稳定保障高速数据传输

XPU Socket 微型互连方案
芯片与主板 / 基板之间超短距互连互连路径极短,全链路信号损耗最低,完美适配超高频率算力信号传输